Artificial Intelligence (AI) tools are becoming increasingly powerful and integrated into our daily lives. From drafting emails to analyzing complex datasets, they offer incredible convenience. However, this convenience almost always comes at the cost of your privacy.
Pretty much all of the most popular AI chat interfaces require you to send prompts over the internet to someone else's servers. While convenient, this raises the obvious concerns:
- Is my data being stored? And how long is it retained for?
- Is it being used for training other models without my consent?
- Can I realistically trust any of these companies to be ethical when using my data?
- How do I know that data protection laws are being adhered to?
This post explores why running AI models locally on your Mac using Ollama and Open-WebUI offers a significant leap in privacy protection, and how you can maximize that security.
The foundation of local privacy: Your data never leaves
The core principle of enhanced privacy with this setup is local execution. Here's why it matters:
- Data stays on your device: When you chat using Open-WebUI on your Mac, the prompts and responses happen entirely on your computer. No data leaves your network unless you explicitly send it.
- No upload required for interaction: Unlike some cloud services where even asking a question involves an upload to their servers, your local interface handles everything.
Concrete steps to bolster your local AI privacy
Ollama is an open-source tool designed specifically to run large language models (LLMs) directly on your local machine, rather than relying solely on cloud APIs. It acts as an API server that pulls and executes models natively installed on macOS.
Open WebUI is an open-source web interface designed to work seamlessly with local LLM services. Think of it as a browser-based dashboard that connects to your Ollama instance, and acts as a replacement for the likes of ChatGPT, Claude and Gemini.
Open WebUI is the frontend delivering a familiar UI so that you don't have to use the terminal, whereas Ollama is the backend, doing all the hard work.
Setup steps
I'm running my business on modern Macs running Apple Silicon (M1/M2/M3). For these, I'm installing Ollama natively rather than through Docker. This approach leverages Apple's Metal framework and Neural Engine for optimal performance.
Installation via Homebrew
I use homebrew for convenience and ease of setup, so to me, this is a good way to install Ollama. You can alternatively download the binary from the Ollama website.
To install on MacOS using Homebrew, open a terminal window and paste:
brew install ollama
ollama serve & # Run in background
ollama pull llama3
This gives you:
- Native performance optimization
- Automatic updates
- Easy model management
Adding the Open WebUI interface
While Ollama runs natively, we'll use Docker for the web interface to maintain flexibility:
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always ghcr.io/open-webui/open-webui:main
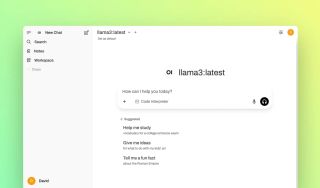
Access your private AI at http://localhost:3000/. It should look something like this:
Expanding your model library
The true power of local AI comes from choosing models that fit your needs. Browse available models at ollama.com/library and install with:
ollama pull [model-name]
Popular options include:
llama3for general usemistralfor compact efficiencydeepseek-r1for coding assistance
Setting up Ollama and Open-WebUI is the first step towards privacy. Here's how you can make it more robust:
Secure network access
Keep services internal: By default, when both run locally via Docker, the communication between Open-WebUI and Ollama stays on your local machine. This is the most crucial step for privacy.
- Why it's private: Your prompts never leave your local machine. Even if someone gains physical access or hacks locally accessible services, they don't see your raw chat data unless you share the device/monitor directly (e.g., peeking over your shoulder).
- How to ensure: Double-check that both
ollama serveand your Open-WebUI Docker container are running. They should communicate internally without needing external network access.
Understand how model providers operate
- Model download vs. user data: Ollama pulls models from its servers (e.g.,
ollama pull llama3) for local execution performance. These model files are downloaded once and used locally.- Privacy implication: While your prompts stay private, the fact that you're running a specific model might be known by the provider. They generally don't use your prompt text (unless explicitly stated) to train their models further, focusing instead on the model architecture itself being available for download and offline use.
- Be cautious with user-to-user models: While Ollama + Open-WebUI provides privacy against third-party upload, if you're using a chat interface that connects users directly (not just pulling pre-downloaded models), ensure that communication between users is encrypted. This might involve additional configuration or alternative tools designed for secure peer-to-peer interaction.
Conclusion: Proactive privacy with local AI
Using Ollama and Open-WebUI together on your Mac provides a good default privacy by keeping all processing local. To further harden this, focus on:
- Keeping services internal.
- Avoiding unnecessary external exposure.
- Using secure tunnels or VPNs only when collaboration demands it.
By understanding these principles and configuring your setup accordingly, you can significantly reduce the digital footprint of your AI interactions and take control of your data's security. Embrace local execution as a powerful tool for responsible AI use.





